MULTIDIMENSIONAL ANALYSIS WITH
RELATIONAL DATABASES.
HOW IS THIS POSSIBLE?
Andy Osborn
Director DSS Technologies
Oracle Corporation
Summary
As businesses look to data warehousing for data analysis and On-Line Analytical Processing (OLAP), a debate has arisen as to the feasibility of implementing OLAP on a relational database. This paper discusses the advantages of implementing OLAP on relational databases such as lower maintenance cost, security, connectivity, and the availability of detailed data. It also outlines how to improve the performance of an OLAP relational database through the use of a metadata layer that maintains pre-aggregated data, smart indexing, minimal client side aggregation, and star schema design. It illustrates this concept using Oracle Discoverer.
1. OLAP and Multi-Dimensional Analysis
The terms OLAP (On-Line Analytical Processing) and multi-dimensional analysis are often used interchangeably, to describe both databases and tools, and there are as many formal definitions of the terms as there are software products that claim to support them.
1.1 Codd’s 12 OLAP rules
The term OLAP was coined by Dr. E.F. Codd, his wife S.B. Codd and their associate, C.T. Salley in 1993 in the research paper "Providing OLAP to User-Analysts: An IT Mandate". This defines 12 ‘rules’ for OLAP as :
- Multi-Dimensional Conceptual View
Data should be presented to the user in a multi-dimensional paradigm.
- Transparency
Users should not need to know that they are using an OLAP database.
- Accessibility
Tools should choose the best source of data to support a query.
- Consistent Reporting Performance
Performance should be the same regardless of the number of dimensions in use.
- Client-Server Architecture
Tools should be deployed in a client server architecture.
- Generic Dimensionality
Dimensions are all equal; there should be no bias towards any one dimension.
- Dynamic Sparse Matrix Handling
Null values should be stored in an efficient way.
- Multi-User Support
Tools should support more than one user!
- Unrestricted Cross-Dimensional Operations
Aggregation rules should be applied consistently across all dimensions.
- Intuitive Data Manipulation
The user views of data should contain everything required without resorting to using menus or multiple trips across the user interface.
- Flexible Reporting
Users should be able to present data in any way they like.
- Unlimited Dimensions and Aggregation Levels
There should be no limit to the number of dimensions and levels in a model.
Like Codd’s 12 previous rules for relational databases, there has been considerable debate about the usefulness, completeness and objectivity of these rules, depending on how well they suited a particular vendors current product offerings. There are several key differences, however, between the 12 OLAP rules, and their relational predecessors.
Rules like
(1) Multi-Dimensional Conceptual View
(2) Transparency
(6) Generic Dimensionality
require specific functionality and it can easily be ascertained whether a particular solution implements these or not.
Rules :
(9) Unrestricted Cross-Dimensional operations
(12) Unlimited Dimensions and aggregation levels
are simply saying there should not be any artificial limitations imposed by a solution. These rules are precise, but may not be necessary, if any such limits are sufficiently large.
Rules :
(3) Accessibility
(5) Client-Server architecture
(7) Dynamic sparse matrix handling and
(8) Multi-user support
are architectural requirements which are more controversial. How important these ‘rules’ are really depends on individual requirements. A single user PC based system may be all that is required for disconnected analysis of the annual sales figures, so do we care that it breaks rules (5) and (8)?
Rules :
(4) Consistent Reporting performance
(10) Intuitive Data Manipulation
(11) Flexible Reporting
are very subjective, and are more like good intentions or aims rather than concrete rules which are either met or broken.
Rule (1) Multi-dimensional Conceptual view, implies that multi-dimensionality is a sub-set of OLAP, but then other rules go on to say how this multi-dimensional view should operate, so the rules are not completely independent of each other.
1.2 The Multi-Dimensional logical data model
Despite Codd’s rules, and the debate about their general applicability, there is now a broad consensus on what it means to be multi-dimensional, and what sort of functionality is involved in supporting a multi-dimensional data model.
In a relational logical data model, data can be visualized as a table, with the rows and columns we are all familiar with. In a multi-dimensional model, data is visualized as a multi-dimensional cube, with dimensions along each axis, and measures in the individual cells. In a personnel database, for example, we may want to analyze the number of staff in each department, in each job grade, over time. This is a three dimensional model (department, job grade, time) with one measure; no of staff:
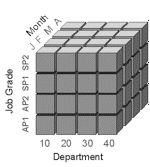
The rules of multi-dimensional models say that we should be able to slice and dice this cube any way we like across any of the dimensions, to answer queries like :
Show the total no of staff in each grade for February.
Show the average no of staff over time for each department and job grade for last year.
Analyze over time the number of people at grade 1 in department 30.
We should also be able to summarize across any dimension(s), and select a portion of any dimension(s), in short we should be able to manipulate the data as a cube, rather than in the relational model, where we manipulate the data as rows and columns.
1.3 Multi-dimensional operations
In addition to the powerful slice and dice operations for data retrieval, multi-dimensional systems also have a rich set of analytical functions for processing measure values, like ranking (top 10, bottom 10), percentage change (growth on same period last year), rolling averages and cumulative totals. Unlike the basic multi-dimensional model, there is no particular consensus on what set of functions is required to conform to any particular degree of ‘multi-dimensionality’, so the functions available on any particular tool tend to reflect the maturity of the tool and the nature of it’s users.
1.4 The Business need
When discussing the differences between different data models it is easy to lose sight of the wider picture. The pace and competitiveness of today’s business environment has caused a huge increase in the need for up to date, accurate information about all aspects of an organization. As well as answering questions to satisfy operation needs (who hasn’t paid their invoices this month, is my department within its budget for hardware), there is the need to identify areas where the business can be improved, where costs can be cut, efficiency improved, new markets exploited, wasted effort identified, sales trends detected and so on. As the volume of data held in corporate databases increases, so a business’s dependence on data also increases, This results in an increasingly urgent requirement for more access and analysis of that data by more and more users across the organization. This requires a great deal of functionality in information analysis tools, of which multi-dimensional analysis is just one part.
2. Multi-dimensional Vs Relational Models
2.1 The Relational Data Warehouse
Typically, the data structures in large operational relational databases have tended to support OLTP better than Decision Support or information analysis. Anyone who has ever been involved in building an OLTP system knows why : data input systems are often implemented before data analysis is really considered, and so the data structures tend to be designed to support the input process, rather than the analysis.
There is also a folklore legacy arising from the use of SQL, that since it apparently allows any form of access to any data in any tables, there is a (false) assumption that it doesn’t matter too much how the tables are structured; we can always figure out the SQL to get data out later. This assumption may actually be true for small volumes of data, but as the volumes increase, so does the need for data structures which are more easily queried. The relational data warehouse is the result; a set of tables, usually extracted from one or more operational systems, combining, joining and summarizing information together in a way which suits people who want to query or analyze the data.
Using the personnel system example, the data could be represented in a relational model in a number of ways; in a relational data warehouse the star schema is the typical organization:
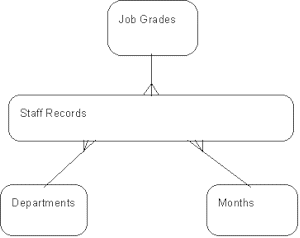
In this model there is a large table at the center of the ‘star’, containing rows for each valid combination of Department, Month and Job Grade. This is where the ‘number of staff’ column is held. The data could be held in a single table, with columns for each of the three ‘dimensions’ held in the same table, but typically numeric keys are used instead to index into smaller ‘code’ tables that form the points of the star. This is simply to save database space since the table at the center may be very large, and numeric keys are usually smaller than natural ones.
When we talk about the relational model consisting of rows and columns, we mean that this is, of course, only a logical model, used to help our understanding of what we can do with the data. Data is not actually stored on disk in rows and columns, although it will be stored in some structured way that can be mapped onto a row and column logical model, when the data is actually retrieved by a user’s query. This is an important point; it means that, in a multi-dimensional system, data should be represented in a multi-dimensional way when it is retrieved - it can be stored in any way we like, as long as we can map it onto a multi-dimensional model at the time of retrieval, and, of course retrieve it fast enough.
2.2 Objections to using RDBMS for Multi-dimensional operations
In the past there have been a number of factors that limit the effectiveness of multi-dimensional operations using a relational database. With current technology, these factors are either overcome, or bypassed using a meta-data layer. Complex, sophisticated OLAP capabilities like trend analysis and forecasting are probably still best implemented directly in a native multi-dimensional database, but ordinary multi-dimensional manipulation of data can now be adequately supported by the combination of a relational database and a meta-data layer that maps the relational schema to the logical multi-dimensional model.
2.2.1 Performance
"Because relational databases manage two dimensional tables there are fundamental performance problems when performing multi-dimensional operations such as slice and dice. Frequent aggregations and joins need to be performed in order to obtain results, both of which significantly reduce performance. Analytical users can lock out OLTP users, and indexes are not optimized for retrieval."
It is important here to differentiate between the logical and physical models. If you need to join and then aggregate 1,000,000 rows of data to satisfy a single rotation of the logical cube, then response is likely to be less than immediate. But if the data is held in a relational warehouse, in exactly the pre-aggregated form to satisfy the query, and can be directly retrieved off disk, then performance will be excellent. Intelligent use of pre-aggregated data to satisfy queries provides exactly this capability.
2.2.2 SQL can’t do multi-dimensional operations
"Relational databases simply can’t do some forms of multi-dimensional queries because of limitations in SQL and the relational model. The two-dimensional model is not intuitive and is difficult to use because it requires joins across many normalized data sets and the user needs to understand a complex database schema. In addition, SQL is not designed to perform time series analysis or complex mathematical functions."
Arguments like this assume that SQL is the interface that the user has to deal with, and that the data structures users see are the raw tables and columns in the database. Users would have to have the knowledge of the database designer to make sense of this, and the expertise of an experienced SQL programmer. This argument assumes the logical model shown to users must be the same as the physical one that the data is stored in.
There is no reason why the user interface to data analysis should be a direct mapping onto the physical structures used for data storage, in fact, because of the complex nature of OLTP database schema design, we actually need to do exactly the opposite if users are ever to exploit the potential in their data - we need to hide the physical structures and SQL access mechanism from the end user. Tools such as Discoverer use a meta-data layer to hide the relational design of an application from users and to present information in business, rather than technical terms. By extending this meta-data layer and making it active, rather than passive, we can provide most multi-dimensional operations directly against the relational database. This is explained further in the next section.
2.2.3 SQL can’t do some sorts of multi-dimensional queries
"Multi-dimensional operations such as ranking (top 10, bottom 10), percentage change (growth on same period last year), rolling averages and cumulative totals do not come naturally to SQL. SQL is inherently non-procedural and cannot be used for these forms of analysis."
Although these types of operations are often found in sophisticated OLAP tools, there is nothing inherently multi-dimensional about them, and all of the above could equally be applied to a one-dimensional relational query. Since these operations are not (currently) supported directly by SQL there are three options for a multi-dimensional/relational tool:
- Implement the function in the front end tool
This is the most obvious choice for cumulative totals, percentage change and other similar reporting type functions.
- Generate the necessary (complex) SQL to implement the function in the server.
For some operations this can be more efficient, requiring fewer rows to be returned to the client.
- Extend the meta-data to provide more direct support
This is useful for direct support of things like ranking, which can easily be stored against pre-computed summary data.
2.2.4 Users have to understand joins and complex schemas
"Relational databases hold information in normalized form requiring users to have knowledge of relational keys and understand how to join tables together."
Again, this assumes that the user interface to data analysis is limited to the schema of the application database . The End User Layer (TM) meta data used by Discoverer handles these and other data structure issues by :
- Grouping associated data into Business Areas that users are familiar with, such as Human Resources, General Ledger and Departmental Information.
- Hiding database concepts such as tables, views, and synonyms by displaying a straightforward list of objects in each business area.
- Renaming objects and adding text to explain the meaning of information.
- Creating automatic joins between objects to hide the relational structure of the data.
- Defining drill relationships to automatically retrieve more detailed information.
Section 3 describes how this meta-data is further extended with Oracle Discoverer, and made active to provide multi-dimensional functionality.
2.3 Benefits of using RDBMS for MD operations
If the multi-dimensional capabilities required by most business users can be met using a relational database as the data store, then there are significant benefits in terms of cost, maintenance, training and system administration.
- OLTP and warehouse data held in the same database
- Wide choice of hardware platforms
- Utilize existing database skills
- Only one system to backup and maintain
- Users see up to date data
- Open access to a wide variety of software tools
- Ease of integration with OLTP production systems
- Robust in dealing with very large databases
3. Extending the Relational Model
3.1 The End User Layer
If the relational model is extended through the use of an active meta-data layer, then we can retain all the advantages of using a relational database, whilst providing an additional user interface to the data through a multi-dimensional query and analysis tool. This is the role of the End User Layer in Discoverer.
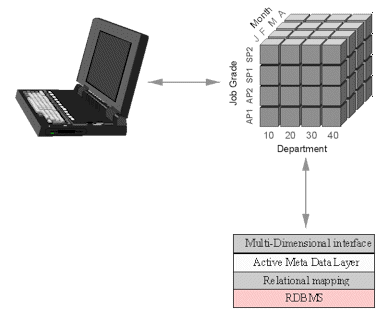
In Oracle Discoverer, the active End User Layer stores and processes meta data which enables a multi-dimensional view of data to be presented to end users, and manipulated through a multi-dimensional interface. The RDBMS is treated simply as a repository for data, with the End User Layer handling all the mapping between the relational schema and the multi-dimensional model.
The End User Layer simplifies, joins, flattens and optionally summarizes data held in the underlying relational database. Multi-dimensional structures such as hierarchies are defined and may then be used for drill down and rollup analysis, with the appropriate SQL generated to retrieve data at the requested level of detail. The user interface to this is via a simple Windows 95 style navigator for picking information and a multi-dimensional pivot table for slicing, dicing, drill down and rollup. The End User Layer uses its knowledge of the database schema to generate the fastest SQL in order to satisfy the query.
3.2 Summarization management
Using the previous 3 dimensional example. we could perform any analysis combining any of the dimensions (Job Grade, Month and Department) with any aggregation of the measure (no of staff). In a normalized relational model this would always involve aggregating the base data unless we actually wanted to view all values of all three dimensions at once. The combinations of dimensions we could choose would be :
Job Grade
Month
Department
Job Grade, Month
Job Grade, Department
Month, Department
Job Grade, Month, Department
For the general case, given N dimensions there are 2**(N)-1 possible ways of combining the dimensions. The number of aggregate rows required depends on the number of valid combinations of dimension values, and the situation is complicated further when the dimensions are actually in multi-level hierarchies, with Month rolling up to Quarter and Year. However there are pruning techniques that can be employed, for example by specifying which combinations of dimensions or levels it does not make business sense to combine, and by not aggregating at all levels, allowing some minimal aggregation from a lower level, where required. . It is also true that the single dimension combinations (e.g. just Job Grade) result in the fewest number of extra rows being added, and also give the biggest gain in terms of performance by avoiding aggregation.
Although there is a trade-off in terms of database space used to hold summaries, this can be made very configurable, allowing an administrator to create pre-aggregated summaries where they will be most effective.
Oracle Discoverer uses summarization management techniques that generate and maintain the required combinations of summaries, and populate meta-data with information describing what summaries are available. Sparse matrices are handled automatically, further reducing space requirements. When a query such as
‘Show total no of staff in Department 10 over the last 3 years’
is asked, the summarization meta data causes SQL generation to be directed towards the pre-summarized data automatically, and the query is satisfied by a simple indexed search instead of a large aggregation. The larger the database, the bigger the benefit of such an approach, and the effect is to make the response times of queries consistently quick, with operations like drill down, slice and dice being performed transparently against the appropriate summary.
4. Summary
By using an active meta-data layer we can map a physical relational database schema onto a logical multi-dimensional model and provide all the core functionality of manipulating a ‘cube’ of data ; pivoting, drill down, rollup, slice and dice and so on.
By using pre-aggregated data we can avoid large scale aggregations and provide consistent performance across a wide range of queries.
In using a relational database to provide these capabilities we can also retain their inherent advantages of flexibility, robustness with large databases, openness, connectivity, lower maintenance cost, ease of administration, and security.