Oracle Discoverer™
Explore New Dimensions
1. Introduction
The information revolution is underway.
Organizations are generating and storing unprecedented amounts of
data about their day to day operations. A new paradigm must be
uncovered to reign in and harness these vast amounts of data.
Furthermore, it is not enough to simply collect and collate large
amounts of data without putting it to good use. With the advent
of data warehousing, organizations have begun to discover new
ways of turning data into a valuable resource. As the leader in
providing information technology, Oracle is at the fore with an
array of technologies to assist in gaining the benefit from data
warehouses. Decision makers at all levels of the organization
must be able to access and manipulate data in such a way that it
can be transformed into an organization's most valuable asset: information.
Oracle Discoverer is the tool that allows business users to
turn data into information.
2. Data Warehousing
Recent surveys indicate that over 90% of mid to
large sized organizations will set up a data warehouse this year.
According to IDC, approximately 80% of organizations that have
already invested in data warehousing, view them as a major
success. Why? A data warehouse provides a distinct
centralized repository from OLTP systems that contains extracts
of vital business data from a variety of corporate databases.
This data is analyzed and used as a strategic competitive
weapon. Fast, accurate analysis of business issues affect
long term survival. For example, analyzing trends in geographic
demand patterns allowed one organization to regulate supplies
accordingly and increase sales by over $2 Million.
Unlike those of operational systems, data
structures in a data warehouse are optimized for rapid retrieval
and analysis. The data is historical and is updated at some
regular interval.
There are 3 general steps to defining, creating
and using a data warehouse:
1) Model end user business needs. The
designers of the warehouse must obtain information needs from the
various business users. The designers translate these information
needs into a warehouse model. Designers must take a rigorous and
disciplined approach to ensure completeness of the model.
2) Model meta-data. In conjunction with
modeling the end users' needs, warehouse designers must also
model meta-data (data about the data). This information defines
the data going into the data warehouse and the rules associated
with this data. Since the data warehouse is subject oriented,
this modeling of meta data might cross functional business areas.
The meta data falls into two categories: loading and user.
a) Loading view: This describes all the data sources and all the rules for extracting, scrubbing, and transporting data to the warehouse.
b) End user view: Here, the model matches the
business uses of the data. This is the floor plan of the
warehouse that end users use to access and explore their
information.
3) Evaluate, determine, and implement
extraction, transformation, and access tools. Once designers
have established a model of the end user needs and accompanying
meta data in the repository, tools must be chosen for stocking
the data warehouse. The final decision entails selecting the
tools that end users will work with to access the information
stored in the warehouse.
3. The Oracle Warehouse
The Oracle Warehouse consists of a suite of
products and services that span the entire process of defining,
designing, and implementing a data warehouse. The figure below
shows the components in the Oracle Warehouse:
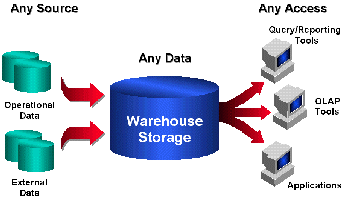
Figure 1 - The Oracle Warehouse
Any Source. The data collected in the
Oracle Warehouse can come from a variety of sources, including
both operational (internal) and external. Traditionally, most of
the data in a warehouse has come from internal operational
systems such as order entry, inventory, or human resource data.
However, external sources (demographic, economic, internet) are
becoming more and more prevalent and will soon be providing more
content to the data warehouse than the internal sources. Both
sources must be harnessed and melded into a single storage
container to provide end users with seamless access to both kinds
of data.
Any Data. Because of the breadth of
users now involved with accessing the data warehouse, system
designers are faced with a diverse set of requirements. Access to
the data must be fast, straightforward, and intuitive. The mass
of users require straightforward query and drill capabilities,
while others require more sophisticated analytical capabilities.
The data source must be able to handle new formats of data such
as audio, video, text and spatial. Furthermore, vast historical
requirements from an increasing number of users frequently leads
to very large databases (VLDBs). To satisfy these requirements,
Oracle provides both a relational (Oracle7) and a
multidimensional (Express Server) solution.
Any Access. Oracle offers a
comprehensive suite of tools that allows all types of users to
access the data held in the warehouse, including: ad hoc querying
and reporting, drill-down and pivot, and full analysis (modeling,
forecasting, what-if analysis, etc.). The majority of users need
a straightforward, intuitive tool that allows them to easily
access the data to make common business decisions. A separate set
of analytical users need to do more sophisticated, lengthy
analysis in support of business strategies. Taken together, the
need to access the information spans an entire organization. The
data warehouse of today has moved from the executive and analyst
domain to include this broad category termed knowledge workers.
This evolution is a direct result of pushing authority down the
command chain; flattening the organization. Given the more
prominent role of the knowledge worker, the decision on which
tools to implement becomes much more critical.
To address this diverse set of knowledge worker
needs, Oracle provides a unique and complete set of business end
user access tools.
Discoverer is the end user query, reporting,
drill/pivot, and web publishing tool that allows users to gain
rapid access to the relational data warehouse allowing them to
make more informed business decisions.
Express AnalyzerTM is the end user
Analysis and web access tool that provides sophisticated analysis
capabilities such as forecasting, modeling and what-if analysis.
Express ObjectsTM is an OLAP
development tool, tightly integrated with Express Analyzer.
- Discoverer - Product Architecture Overview
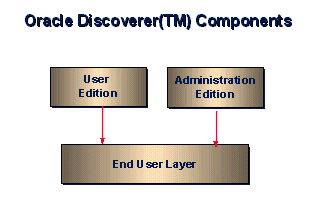
Figure 2 - Discoverer Architecture
Discoverer is comprised of 3 main elements:
1) User Edition
2) Administration Edition
3) End User LayerTM
4.1 Discoverer - User Edition
The User Edition enables users to query the
warehouse, graph results, create reports, perform drill and pivot
analysis and publish results to the World Wide Web. Given such a
fundamental role, this module must meet a number of end user
requirements.
During design and development of the End User
component, Oracle focused in 3 key areas:
- Ease of Use
- Performance
- Flexible Warehouse Exploration
4.1.1 Ease of Use
For non-technical, business-oriented end users,
usability of access tools is the single most important
consideration. Discoverer provides a unique interface, where you
interact directly with the data you are familiar with. There is
no requirement to go to a separate conceptual dialogue to pivot,
or a separate "drill mode" to drill.
4.1.1.1 User Interface Development
A Unique Approach.
Traditionally, engineering focus has been
primarily on the technical integrity of the product being built.
As an integral part of development of Discoverer, the software
engineers were exposed to customer and user feedback in a variety
of ways. Such exposure introduced a newfound understanding of the
manner in which end users would like to interact with their data
warehouse access tools. Based upon this understanding, an
entirely new approach to development was taken with Discoverer.
Prototyping Design Possibilities.
Early in the development process for
Discoverer, paper prototypes were used extensively by a
specialized group of User Interface design professionals. Paper
prototypes of the user interface were shown to testers,
marketers, product managers and potential customers in an effort
to solicit input on areas such as ease of use and intuitiveness.
Based on this early feedback, the proposals evolved until a basic
prototype design was settled upon.
Focus Groups and StoryBoards.
Once the paper design phase for Discoverer was
completed, the User Interface (UI) design group used software to
build 'mock' screens or StoryBoards in order to solicit
more advanced feedback about how users interact with the tool.
The purpose of the Focus Group was to gain a better understanding
of a user's thought process when faced with performing a
specific task. For example, 'How do I extract information about
last years sales figures for the East and West Region and produce
a meaningful report with summary totals?' The user interface
continued to be tailored according to this feedback. Once the
members of the UI design team were satisfied with the interface,
the software engineers started coding.
Usability Laboratories.
The usability focus of Discoverer did not stop
with Focus Groups. Throughout the development of the project, the
UI design team has run several usability tests with a broad range
of users from various technical backgrounds. This ensured the
development team received constant iterative feedback and could
keep focus on the usability of the product. Usability testing
allows developers to further refine the interface by providing
real-world insight into issues and concerns that affect end
users. Current and future development of Discoverer will continue
to leverage the benefits of extensive usability testing.
4.1.1.2 Usability
The net result of this innovative approach to
development is an interface that provides unsurpassed usability
with an intuitive look and feel.
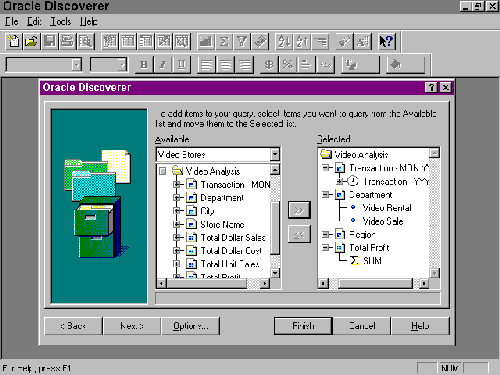
Figure 3. Discoverer User Interface
Wizards, Cue Cards and Quick Tour (CBT)
Discoverer uses a modern wizard-based approach
to lead you through each step of the query building process.
Wizards greatly simplify common tasks. Additionally,
task-oriented assistance in the form of cue cards and computer
based training ensure a minimal training curve for new users. Via
the newly designed interface, you produce results immediately
with no supervision.
Single User Interface for Queries, Reports, and Exploration.
Unlike many products, Discoverer provides one
consistent interface for querying, reporting and drill down/pivot
functionality. Discoverer blurs the distinction between these
approaches, enabling an inexperienced user to retrieve and
analyze information without understanding the conceptual
differences and terminology of these technologies.
Windows95 Features.
Discoverer incorporates the advanced ease of
use features of Windows95: drag and drop information into a
query, using the right mouse button for shortcuts and saving
results using long filenames and extensions, to name a few.
The key aspect of the user interface is that
you interact directly on the data they see before them - there is
no separate conceptual dialogue to use to either
"slide-and-dice" or drill. The net result is superior
overall usability which frees you to become immediately more
productive.
4.1.1.3 End User Layer
The End User Layer is a server based,
low-maintenance, powerful mechanism for providing end users with
a business-oriented view of the data warehouse.
The End User Layer :
1) Abstracts the complexity of the underlying database structures.
2) Defines drill down and other related analysis information.
3) Automatically creates and maintains summary tables.
4) Enables automatic query redirection to
summary tables.
Hiding Complexity
Without the concept of an End User Layer, you
are forced to access their relational data directly using SQL.
You need to understand underlying relational database structures
such as tables, columns, joins, etc. For a small subset of users
who are technically experienced, this is perfectly acceptable.
However, the knowledge workers of today span all functional areas
and technical abilities. Clearly, we need a way to mask the
underlying complexity of the database to provide end users with
an interface they can easily understand. The End User Layer of
Discoverer provides just such a mechanism.
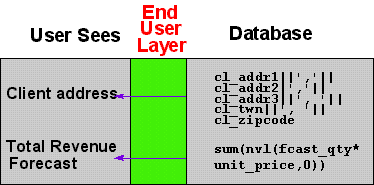
Figure 4. The End User Layer
Via the End User Layer, Discoverer is able to
logically group together related sets of information in the form
of Business Areas. A Business Area may contain, for
example, personal data, departmental data (Sales, Marketing,
Finance), data relating to a specific topic (Customer
information), and so forth. While the underlying technical
definition of a Business Area may contain as many
references to database objects as desired, users interact with
terminology and business groupings that they understand.
Subsequent levels of detail are grouped in a hierarchical manner. A Business Area comprises a number of Folders (roughly analogous to database tables or views) which in turn contain a number of Items (roughly analogous to database columns). Relationships between folders, (corresponding to joins between tables) are created automatically in the End User Layer based on referential integrity constraints in the RDBMS, or on matching column names. A Folder can also group columns from different tables into a single logical unit known as a Complex Folder. This flexibility allows the meta data in the End User Layer to be set up in the manner that best suits the business-oriented end users.
Drill Down and Other Analysis Information
More importantly, the End User Layer allows the
administrator to define informational structures that do not
exist in the online database data dictionary. These structures
direct users to easily do further analysis of the data, such as
drilling and slice-and-dicing. Examples of these additional
informational structures include hierarchies, computed items,
additional joins and alternative sort orders.
Hierarchies
The RDBMS data dictionary holds meta
information such as column length, precision etc., but lacks
information on how items are related to one another. Areas of
business data are naturally related to one another in some
hierarchical way. For example, Regions can be broken down into
States, and States into Cities, and so on. Similarly, employees
have managers, managers have supervisors. When exploring data, it
is extremely useful to traverse up or down these hierarchies
looking at increasing or decreasing levels of detail.
The End User Layer allows us to define these hierarchies. There are two basic types of hierarchies:
- Item hierarchies - define relationships among columns (Regions, States, Cities)
- Date hierarchies - define relationships among
date formats (Years, Quarters, Months)
Computed Items
In general, data that is useful to users may
not exist explicitly as a column in the database. Frequently this
data must be derived from existing database columns. A simple
example is a data item such as Profit which may be defined as
'Revenue - Cost'. Computed items are expressions pre-defined in
the End User Layer or created at run time based on existing
columns in the database. The complexity of the calculation is
hidden from end users.
Alternative Sort Keys
In business practice, there is a common need to sort data by non-conventional methods. Alternative sort keys enable you to define the sort order for your information. One example of this is in the financial world, where months may be defined as M1 to M12. The alternative sort key provides an automatic mechanism for ensuring these dates are sorted correctly in every circumstance.
Summary Tables
Summary tables greatly enhance the performance
of information retrieval in a large volume data warehousing
environment. In a relational database, users often summarize
detail data "on the fly" to find aggregate values. This
results in time-consuming and resource intensive queries that
dramatically affect performance of the system. Factor in that the
typical system supports dozens, hundreds, or thousands of users
performing similar types of queries and it becomes clear that a
better solution is required. Using Discoverer, you can create and
maintain pre-summarized data, and the automatic summary
redirection capability reduces the amount of data to be searched
while also reducing (or eliminating) the need for extensive
calculations. The implementation of summary tables are just one
of the many features of Discoverer geared towards improving
performance.
4.1.2 Performance
One clear result from the usability tests and
focus group feedback is that performance is ultimately a
usability issue. If an end user access tool does not provide
rapid response times, it will be summarily rejected by users.
Discoverer is a breakthrough development which resolves the
performance issues common with many end user access tools in the
market today.
4.1.2.1 A Solution to Long Running Queries
Data warehouses are typified by large amounts
of data and an ever growing number of users which both contribute
to increasingly long running queries. Discoverer provides two
mechanisms for reducing the negative impact of long running
queries.
Reactive Query Governor
A reactive query governor allows end users or
administrators to set an upper threshold on query execution time.
If a query is still running when the time threshold is reached,
the query is automatically terminated and valuable system
resources are released. Clearly, such a safety device is
imperative, yet it provides only part of the solution for dealing
with long running queries. The shortcoming of this mechanism is
that the query runs, tying up system resources until the
threshold is hit, at which time the query is terminated. The
requesting end user is forced to wait and is ultimately left
without the query results. To effectively deal with this
situation, Discoverer also employs an altogether different and
unique type of query governor.
Predictive Query Governor
The predictive query governor in Discoverer
provides an estimate of the retrieval time before a query
is run. If the query is predicted to take longer than a
user-defined time threshold, Discoverer warns you and allows you
to determine if the query should be run. This feedback enables
you to make sensible decisions on whether to run a query
immediately or refer it to a batch process for later calculation.
Valuable system resources are conserved, overall load is reduced,
and end users wait less.
4.1.2.2 Summary Tables and Automatic Summary Redirection
Summary tables are required to ensure
performance against large volume data warehouses. Issues on
summary table creation and maintenance are discussed later, under
section 4.2.3 Summary Management.
Assuming that summarized tables are available,
the question then becomes how to gain the maximum benefit from
them.
Discoverer provides a major breakthrough in
this area, providing the first true automatic summary
redirection capability. As users issue requests for
summarized data, Discoverer checks to see if the requested data
has already been pre-summarized. If so, the query engine
generates and issues the appropriate SQL and the query is automatically
redirected to run against the summary table containing the
pre-summarized data. If a table doesn't exist, Discoverer
ascertains the closest summarized match down the hierarchy, and
aggregates from that level. This unique capability provides rapid
response times and lightens load on the server, without any
effort from either the user or administrator.
4.1.2.3 Client Side Cubic Cache
Discoverer employs a sophisticated client-side
cubic cache that enables rapid analysis without re-querying the
database. Using the benefits of the client/server architecture,
the results of a query are compressed and indexed in a memory
efficient cubic cache, completely transparent to both end user
and administrator. The local storage (caching) allows end users
to ask subsequent questions about the data without having to
re-execute the query on the server. While a user rotates or
reformats the data, all processing is handled locally to provide
exceptional performance. As additional data is requested by the
user, Discoverer fetches only the newly requested data and
incorporate it into the existing cache. Support for multiple SQL
statements enables the results of additional queries or measures
to be dynamically added to the cache without re-querying existing
data. As more data is retrieved, unwanted data is seamlessly
removed on a least-recently-used basis to ensure the cache does
not grow endlessly. The cache supports any number of dimensions
or measures and users may specify it's physical size and
location.
4.1.2.4 Leveraging Oracle7
Data warehouse applications require different
processing techniques than OLTP applications due to the complex,
ad hoc queries running against large amounts of data. To address
these special requirements, Discoverer™ can directly
leverage the rich variety of query processing techniques (e.g.,
bitmapped indexes, hash joins), sophisticated query optimizations
(e.g., support for "star" and "snowflake"
schema's), and scaleable architecture of Oracle7.
4.1.3 Flexible Warehouse Exploration
Many types of data analysis involve exploring
deeper levels of detail in a given area of information. This
operation is commonly known as a "drill." The drill
paradigm in Discoverer is unique in that it employs a
"Just-in-time" strategy analogous to browsing the World
Wide Web. Warehouse administrators are not forced to predict
which areas of information end users will need to work with, in
the same way as an individual browsing the web is not forced to
stay within some pre-defined set of web pages. The only data
queried from the server and brought over to each client machine
is the data explicitly requested by the user - nothing more,
nothing less. Large amounts of unnecessary overhead for both
administrator and system are avoided altogether. The
"surfing" metaphor of the World Wide Web precisely
describes the information retrieval paradigm in Discoverer.
4.1.3.1 Conditional Drills
To further increase the power and flexibility
of the drilling mechanism, Discoverer includes support for a
number of different styles of drill. Discoverer supports conditional
drills, enabling you to drill from one level of detail to another
according to some subset of the information, greatly reducing the
amount of data received. For example, rather than simply drilling
from region (North, South, East, and West) to detailed
information for all regions, a user may only need to drill to
detailed information for the North region. Conditional drills
also allow you to drill to any level of detail, bypassing
intervening levels. Consider an example with Country, Region,
State, City. You may want to drill from Country level data
directly to city level data without first having to fetch data
pertaining to region and state. Discoverer frees you to explore
the information you need, when you need it.
- HyperDrill (Drill to Detail)
A complex issue in data warehouse access tools
today is the requirement to drill through different levels of
summarized data down to detailed rows (e.g., drill down a
variance report in your general ledger to find the detail
invoices that cause anomalies). Discoverer resolves this issue by
providing a unique HyperDrill capability to rapidly
drill from summary information to detail rows in the relational
database.
4.1.3.3 HyperDrill Plug-In (Drill Out)
In an extension of the HyperDrill capability,
Discoverer also supports drill out to external applications via
the HyperDrill Plug-In. For example, users may drill out to a
multimedia application, a Microsoft Word or Excel application, or
to their favorite World Wide Web browser.
4.1.4 Web Enabling Discoverer
Disseminating information quickly and easily
throughout the enterprise is critical to the success of any
business, and the World Wide Web (WWW) is rapidly becoming
recognized as the most powerful and cost-effective mechanism to
achieve this. Extending the multidimensional analysis model of
Discoverer to the World Wide Web (WWW) has a number of
advantages:
- Fast and easy distribution to any business user with a WWW browser. The user does not have to be a Discoverer user.
- Lightweight and readily available from virtually any model of PC. By eliminating or postponing hardware upgrades, organizations can save money and re-use existing computer equipment.
- Portability to all client platforms
4.1.4.1 Web Publishing
Web Publishing is the ability to publish an
existing workbook or report seamlessly to the world wide web.
Reports from Discoverer are exported to the file system as HTML
(Hyper Text Markup Language). Any user who has access to a web
server can use a supported web browser to access this
information.
Web publishing is the simplest way to enable
data-access via the WWW. It boasts a number of advantages:
- Simplicity - It is very easy to generate HTML; all classes of users, from novice to experts, can accomplish this.
- Portability - the generated pages can be read on any client - Macintosh, Motif, Windows.
- Lightweight - the file sizes are
small which does not cause a huge overhead on the system.
4.2 Discoverer - Business Administrator
The Administration Edition of Discoverer is
used for the initial setup and ongoing maintenance of all aspects
of the End User Layer. The administrator performs a variety of
tasks including maintenance of business areas, folders, summary
table creation, and end user access. Clearly, the implementation
of the administration tools are a critical success factor when
setting up the end user environment.
During design and development of the
Administration Edition, Oracle focused in 3 key areas:
1) Ease of Use
2) Server Based Administration
3) Summary Management
4.2.1 Ease of Use
The unique approach to UI development of the
User Edition is carried across to the Administration Edition.
With the same User Interface design engineers concentrating on
the interface, the Administration Edition features similar
usability features that are found with the End User component. An
administrator is free to concentrate on the tasks at hand rather
than uncovering the intricacies of the tool. Most common
administration tasks can be accomplished either by default via
the Wizard-based, Windows95 style interface.
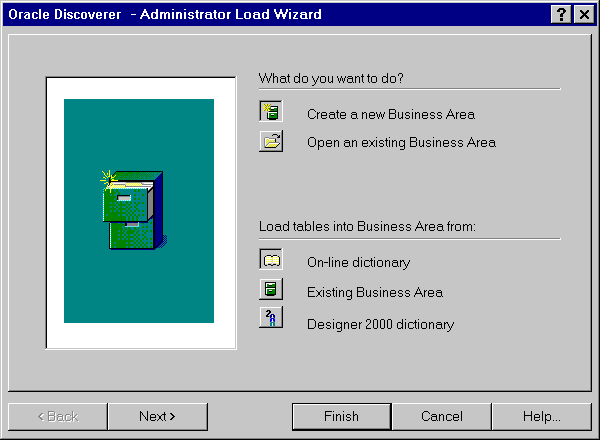
Figure 6 - Discoverer Administration Edition
User Interface
4.2.2 Server Based Administration
The administrator's primary task is the
creation and maintenance of the End User Layer. The
implementation of the meta layer in Discoverer has key advantages
for administrators:
4.2.2.1 Central Database Repository
The data and data structures that comprise the
End User Layer are all stored in the database on the server. A
server based meta layer provides administrators with one central
repository for maintenance, rather than worry about the
distribution nightmares of a client/file based meta layer.
4.2.2.2 Easy to Create, Maintain, and Access
The emphasis on the user interface and
usability of the tool has ensured the creation and maintenance
process is the simplest possible. Accessing the single,
server-based End User Layer is as easy as connecting to the
database.
4.2.2.3 Scalable
Since the End User Layer is comprised of
database schema objects stored in the relational database, the
model scales precisely as well as the database scales. This is an
important consideration as data warehouses grow rapidly in both
size and amount of users.
4.2.2.4 Leverage Security of the RDBMS
Relational databases have matured over the
years and now provide rich security mechanisms. Administrators of
the End User Layer can directly leverage the security features of
the underlying database such as end user access to the database,
tables, and so on. No separate security model is required, along
with the learning and maintenance headaches associated.
4.2.2.5 Support Any Schema Design
Administrators can build up the End User Layer
regardless of how the data structures in the database are set up.
Users are presented with a uniform view of the data even as
underlying database structures change.
4.2.3 Summary Management Strategy
Discoverer uses summarization management
techniques that generate and maintain the required combinations
of summaries, and populate meta-data with information describing
what summaries are available. Sparse matrices are handled
automatically, further reducing space requirements. When a query
such as
'Show total no of staff in Department 10
over the last 3 years'
is asked, the summarization meta-data causes
SQL generation to be directed towards the pre-summarized data
automatically, and the query is satisfied by a simple indexed
search instead of a large aggregation. The larger the database,
the bigger the benefit of such an approach, and the effect is to
make the response times of queries consistently quick, with
operations like drill down and pivot being performed
transparently against the appropriate summary.
However, this raises several issues for administrators:
- How do I know which summary tables are required?
- How do I build and maintain these summary tables?
- How do I ensure these are always utilized?
The task of creating summary tables is also
daunting. For the general case, given N items (or columns) on an
axis of a cross-tabular report there are 2(N)-1
possible ways of combining the items. The number of aggregate
rows required depends on the number of valid combinations of item
values, and the situation is complicated further when the items
are in multi-level hierarchies, with Month rolling up to Quarter
and Year. However, there are pruning techniques that can be
employed: for example by specifying which combinations of
dimensions or levels do not make business sense to combine, and
by not aggregating at all levels, allowing some minimal
aggregation from a lower level, where required. It is also true
that single dimension combinations result in the fewest number of
extra rows being added, and also give the biggest gain in terms
of performance by avoiding aggregation.
Although there is a trade-off in terms of
database space used to hold summaries, this can be made
configurable, allowing an administrator to create pre-aggregated
summaries where they are most effective. The administration
utility in Discoverer makes this process more manageable.
Overview of Summary Table Creation
As end users issue requests to the warehouse,
on ongoing audit is gathering statistics about those queries
(tables hit, number of rows, etc.). An internal algorithm
monitors these statistics, determines inefficient access paths to
the warehouse tables and makes suggestions to the administrator
regarding appropriate summary tables. Along with recommendations
for summary tables, the administrator is also presented with a
space usage estimate of each recommendation. Administrators then
make informed decisions regarding the space trade-off of such
summaries. The summary tables the administrator chooses to accept
are then created and populated automatically at a time
specified by the administrator. The only thing left for the
administrator to do is specify the interval upon which the
summary tables should be refreshed (nightly, weekly, etc.).
Discoverer becomes immediately aware of the newly created summary
tables, with subsequent user requests for that data being
automatically redirected to the summarized data.
This summary management also provides the
ability to skip levels of summarization within a hierarchy, to
reduce space usage. The automatic summary redirection capability
then instantly aggregates data from the next summary table
available, providing an unbeatable combination of local
aggregation and server-based summary data to gain the maximum
benefit for both performance and space management.
The normally daunting task of summary table
administration is made automatic for administrators with
Discoverer.
5. Summary
5.1 Superior Ease of Use
The focus placed on usability during the
development process of Discoverer has produced an end user tool
that frees end users and administrators to focus on the task at
hand by reducing the learning curve with an easy to use,
intuitive interface.
5.2 Optimal Productivity
The usability of the interface coupled with
unique performance features automatically gives users greater
productivity. For end users the faster response times, an easy to
user interface, and a business-oriented view of the data
warehouse all contribute to an increased ability to make better
informed decisions faster. For administrators, the same easy to
use interface along with powerful administration and
summarization strategies reduce administration overhead and gives
greater flexibility to the warehouse environment.
5.3 Leverage Existing Investment
Discoverer is a key component of the Oracle
Warehouse. It's technology directly builds upon and extends
existing Oracle technology. Tight product integration exists
between Discoverer and Designer/2000 to load and maintain the End
User Layer. Existing in-house technology and expertise with
operational systems can be leveraged with emerging data warehouse
projects. Key technologies of Discoverer, such as the End User
Layer and summarization techniques, will become standard in the
Oracle Warehouse. Within the Oracle Warehouse, Discoverer extends
existing technologies and will serve as a cornerstone as we look
ahead.
Availability
Discoverer is available on Windows 95 and Windows NT. A Windows 3.1 version and full-featured web version will be available shortly.